Summarization
In this stage we take the encoded fragments and we summarize each of them separately. Then, we decode them, so we get again actual words instead of real numbers.
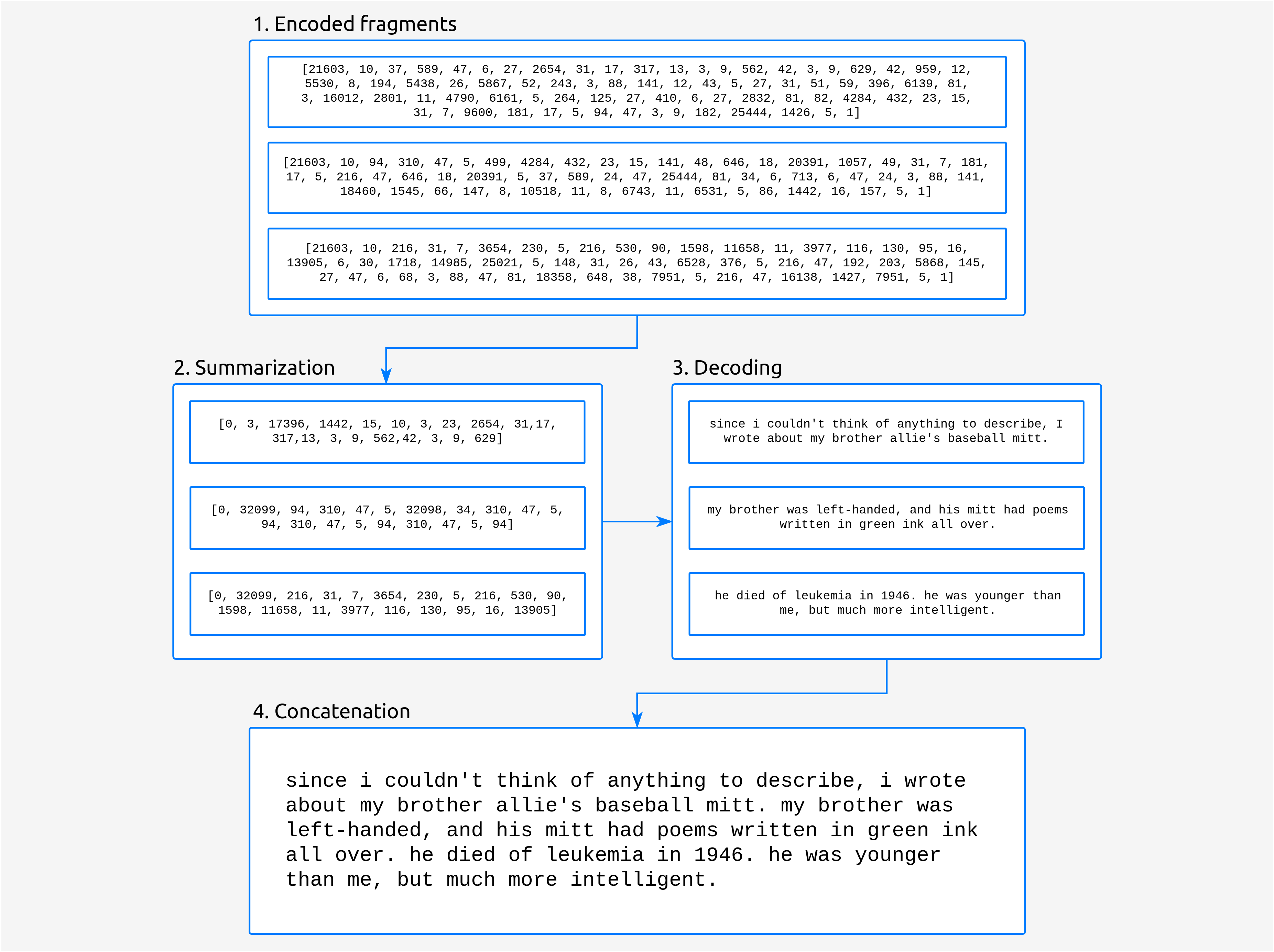
Fig. 4 Once we get the partial summaries from the model, we decode and concatenate them.
As the T5 model that we use is uncased the final summary obtained at this point is all in lowercase. This is something we deal with in the next stage, the post-processing, so the summary returned to the user is correctly cased.
If you curious about how these language generation models work, we recommend to read this fantastic article by Hugging Face on the different decoding strategies used in transformer-based language models.