Introduction
The generation of summaries is divided into four fundamental stages:
Pre-processing: in this stage, minor modifications are made to the input text to adapt it to the input expected by the language generation model.
Encoding: generation models do not “understand” natural language words as such. Therefore, it is necessary to convert the input text to numeric vectors, which is what the model can actually work with.
Summarization: in this stage is when the actual generation of the summary takes place. We currently use Google’s T5 model implemented by Hugging Face.
Post-processing: the text produced by the model may contain small flaws. For example, some models are not cased, which means that they will most likely write all the words in lowercase. In this stage, we try to solve this kind of problems, in our case using a truecaser model, which is able to fix the text casing.
The following picture shows an overview of the different stages:
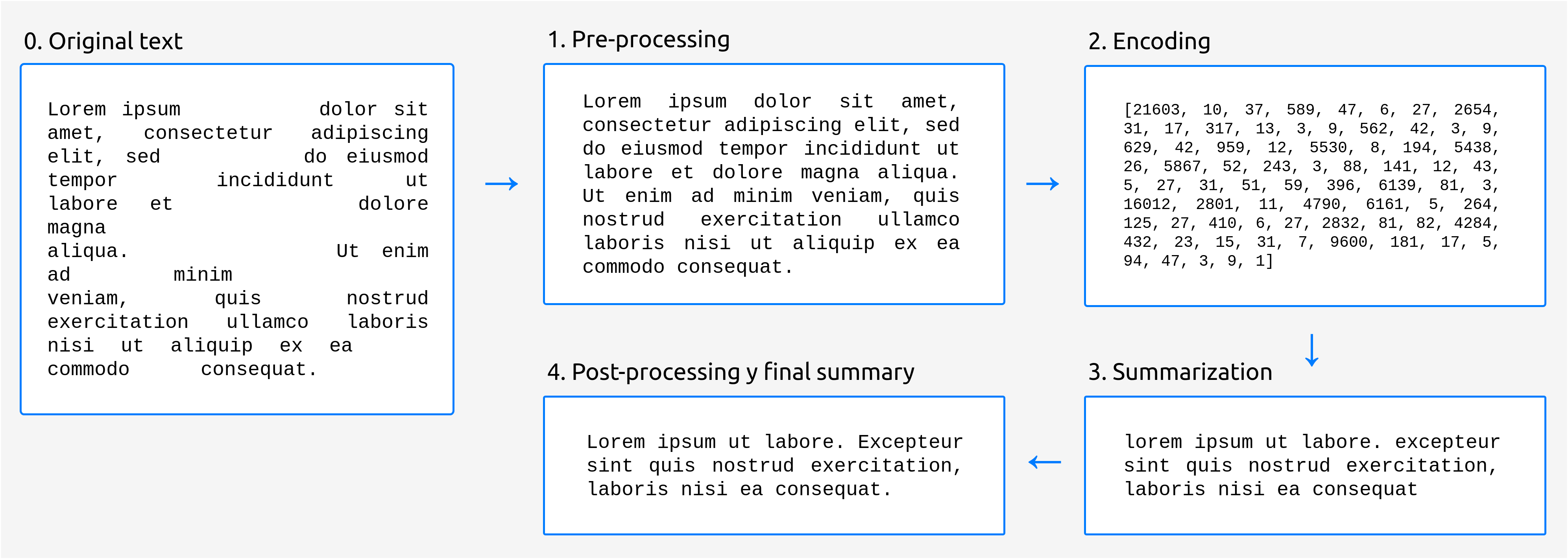
Fig. 1 Stages in the summarization process.