Encoding
As we mentioned before, AI models generally work with numerical representations. Word embedding techniques focus on linking text (either words, sentences, etc.) with real number vectors. This makes it possible to apply common architectures within AI (and especially Deep Learning), such as Convolutional Neural Networks (CNN), to text generation. This idea, conceptually simple, involves great complexity, since the generated vectors must retain as much information as possible from the original text, including semantic and grammatical aspects. For example, the vectors corresponding to the words “teacher” and “student” must preserve a certain relationship between them, as well as with the word “education” or “school”. In addition, their connection with the words “teach” or “learn” will be slightly different, since in this case we are dealing with a different grammatical category (verbs, instead of nouns). Through this example, we can understand that this is a complex process1.
Apart from that, in this stage, once we have the sentences divided from the previous stage, we now are able to:
Split the text in smaller fragments, so we don’t exceed the model’s maximum sequence length. This division is made, as we said, without splitting any sentences.
Encode each of these fragments separately. The encoding itself is made by the T5 Tokenizer provided by Hugging Face.
Summarize the encoded fragments (this is carried out in the Summarization stage).
Concatenate these partial summaries so we end up with a single summary. As we always keep the order of the text fragments, this resultant summary will be cohesive and coherent.

Fig. 2 Detailed steps in the summarization process. Text taken from The Catcher in the Rye.
Something worth mentioning is that, while keeping the sentences complete, we ensure that each all the fragments contain roughly the same number of sentences. This is important because otherwise, some of the partial summaries could be too short.
For this, we first split the text eagerly, attending to the maximum sequence length, and then we balance the number of sentences each fragment, keeping the order. The following figure shows an example with a maximum length of 100 tokens.
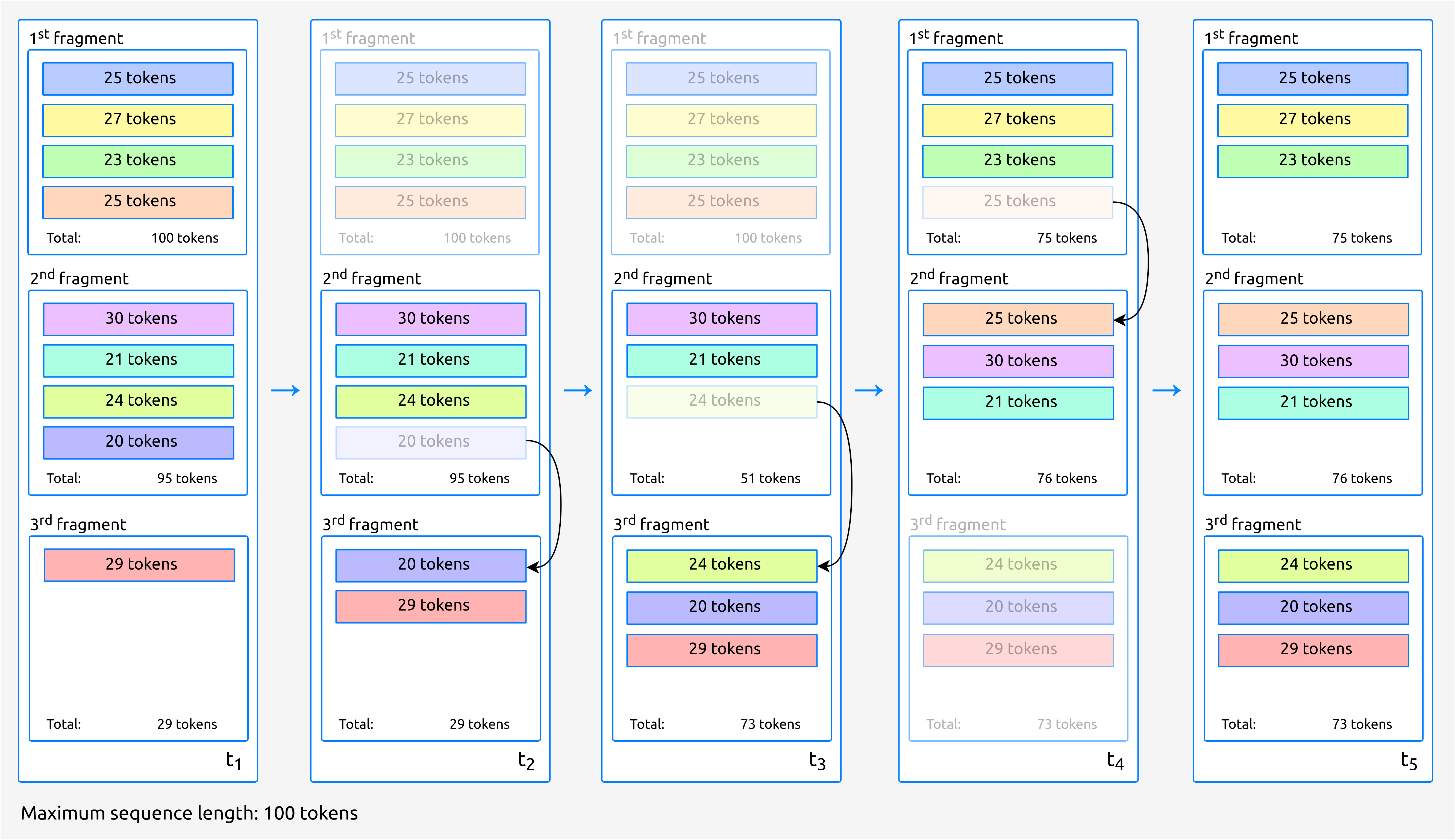
Fig. 3 Once we have divided the sentences eagerly, we balance the number of sentences in each fragment.
In the previous example, the standard deviation in the number of tokens between fragments begins being \(\sigma_1\) = 39.63 and at the end is \(\sigma_5\) = 1.53.